Bad Bohemians
Solo Project
Taking a stab at the procedural whodunnit...
Key Achievements Designed a generator to set (and solve) uniquely-determined logic puzzles, themed as murder mysteries. Optimised its constraint solver within an inch of its life, using SIMD and other low-level CPU tricks. Added grammars, plus a custom lightweight markup, to write the puzzles' procedural text.
Made With Godot, C++.Bad Bohemians is a logic puzzler, in the vein of Return of the Obra Dinn and the Golden Idol series. What's different here is Bad Bohemians' whodunnits are entirely procedural: each has been generated by the computer, at runtime, without any human oversight. It is, at least in theory, an endlessly replayable murder mystery, in which the player has to piece together each suspect's identity (their forename, surname, etc.) from their eyewitness accounts of the evening at hand.

The Usual Suspects A procedurally-generated line up of characters.
In its current state, Bad Bohemians is still the stereotype of a programmer's game: the art is amateurish, the audio non-existent, but god has it been optimised to hell and back. Some of these optimisations, like my use of Streaming SIMD Extensions (SSE) and my abuse of uint64_ts, make Godot particularly angry when trying to export it for web, so the demo is Windows-only for now. Like any stereotypical programmer's game, though, it might still be more impressive to read about than actually play...
First Drafts
This project's been a long time coming. Bad Bohemians started out back in 2022, when I came up with it as a way-too-ambitious project for one of my Master's modules. Naturally, this early prototype had some differences (it only ran in a console, for a start!), but the structure of the generator remains the same. Starting with a constraint solver, we generate a bunch of clues, find a subset that lead the solver to the correct answer, then iterate that subset until the puzzle is challenging enough. First time around, that iteration was done with a genetic algorithm; the solver underpinning it a rules-based system based off of "if-then" statements, that in hindsight would've been far better implemented in a functional programming language than it was in C#.
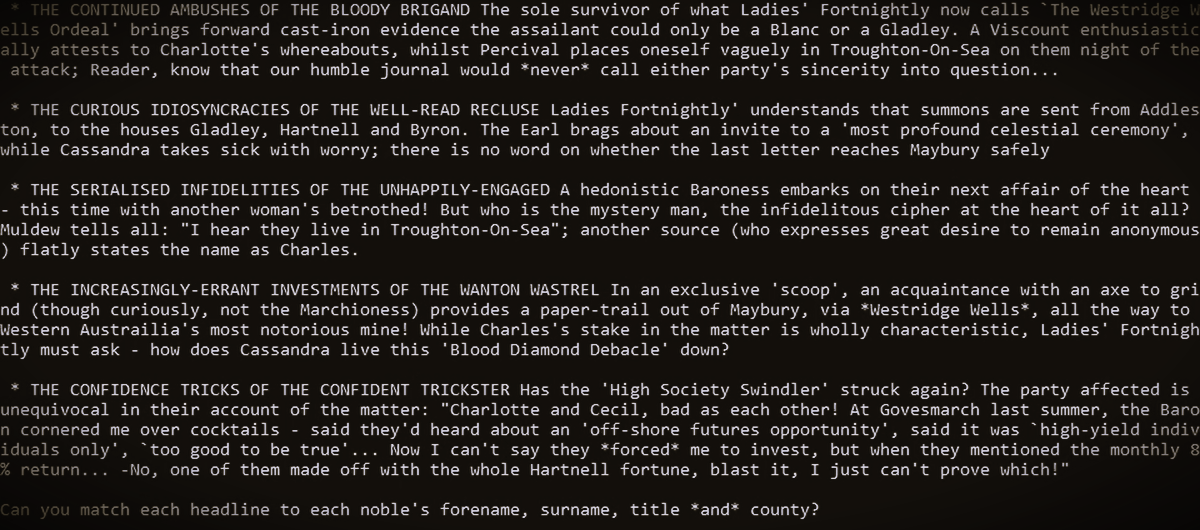
Text-Based Misadventures An early, text-only puzzle, generated with Bad Bohemians' original genetic algorithm. Back then, the puzzles were framed through the lens of a gossip column, with players matching different rumours to different members of the landed gentry.
The project might have got an A+, but even at the time it had some pretty glaring faults. The solver was slow, the text generation rigid, the genetic algorithm unlikely to produce optimal mutations - indeed, I barely had a metric for what an optimal mutation would actually be. Though I would triaging where I could to meet my deadline, I knew that meaningfully improving these puzzles would take redesigning the entire generator, swapping out its C# for C++, and ekeing out the performance needed for more narrative complexity. So that's what I did.
Getting the Story Straight
What makes a puzzle puzzling? What are its key qualities, and how could one describe them in ways a computer could understand? It can't be over- or underdetermined, for a start; a whodunnit needs a single, consistent solution. In an essay on designing Desktop Dungeons' procedural dungeons, Danny Day frames solvability as a matter of decency. Players need to trust that Bad Bohemians respects their time, and that trust will rightly evaporate if we ever present them incomplete or contradictory information. So, the puzzles must be solvable - but they can't be too solvable. The challenge of a game like Obra Dinn comes from having to cross-reference your sources of information, from uncovering its story piece by bloody piece; no single clue gives too much away. In Bad Bohemians, I've formalised all of these design requirements into not-insubstantial code...
One of the first steps in fleshing out my prototype into a full demo was refactoring its solver in C++. Conceptually, it now treats the space of possible solutions to a given puzzle as a dictionary of possible character traits, each with an upper and lower bound on how many characters display said trait. In Bad Bohemians' case, these bounds might translate as "No more than two characters are from the Caine family" or "There are no Dukes called Abigail", statements of that nature. Crucially, the construction allows us an easy check for underdeterminedness. Defining the ambiguity of a puzzle as the sum of all the solver's maxima, minus the sum of all minima, we can then clearly see a puzzle has a unique solution if and only if it has zero ambiguity.
Similarly, consistency can be framed as "not contradicting the bounds". As we propagate information through the solver, our bounds will get tighter and tighter. However, if a minimum gets raised to be higher than its maximum, or vice versa, the solver will terminate early, telling the rest of the generator it's been fed contradictory information and is thus overdetermined.
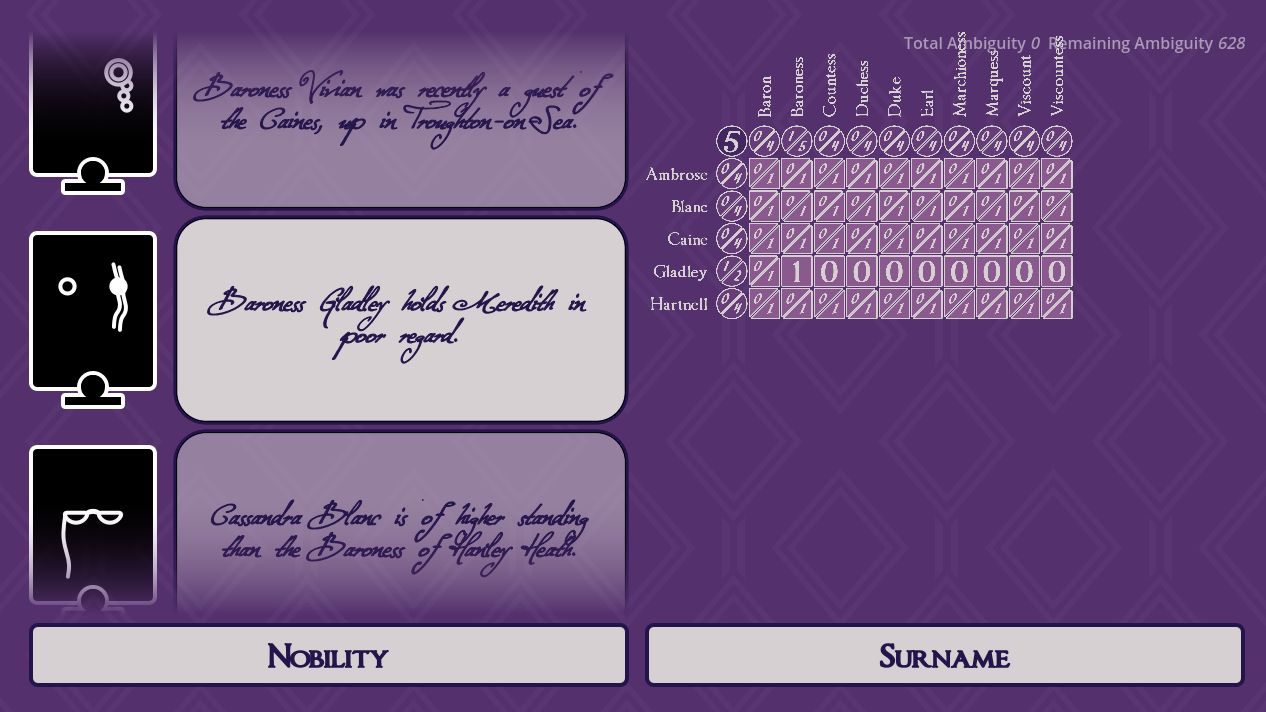
Little Grey Cells A debugging tool for visualising of the solver's grid structure: each cell shows the range of characters with a certain set of qualities (in this case, how many of a given nobility also have a given surname). Individual clues can be toggled on and off to see what the solver infers from each one, helping spot logic errors.
Let's now define another term. Let a be the ambiguity of a solver before any clues have been fed in, and an its ambiguity once only our nth clue has. We might then think of a − an, the reduction in ambiguity thanks to n alone, as the obviousness of clue n. Moreover, we define the obviousness of a puzzle as the sum of obviousnesses of its clues. This number represents how much information is given to the user prima facia, that doesn't need deduced by cross-referencing clues; to optimise a puzzle is to minimise its obviousness. Indeed, the gold standard of puzzle is one with obviousness strictly less than its initial ambiguity: satisfying the inequality Σn(a − an) < a means a puzzle encodes, quite literally, more information than the sum of its parts!
When the generator writes a new clue (more on text generation below), it can be evaluated in terms of these three metrics. After first verifying the clue is consistent, we check if swapping it with any existing clue will reduce the ambiguity of a puzzle, or reduce the obviousness without its ambiguity increasing; if either condition is met, we make the substitution. Perhaps unsurprisingly, this is the bottleneck of the whole generation process. The problem with defining a clue's quality relative to the state of the solver (a solver that contains tens of thousands of bounds that it needs to tighten every time it receives information, I might add), is that actually determining the quality of hundreds of clues involves running that solver over and over and over. It's not ideal. Bad Bohemians can reliably write puzzles for a cast of six characters in somewhere between 30 second to one minute, but it really, really struggles to introduce a seventh. From profiling, though, the solver is running fast enough - it's just running too often. The current set-up is better than the genetic algorithm I was using before, sure, but it still isn't converging on an optimal set of clues as much as it's taking shots in the dark and eventually getting lucky.
Good Grammar
It's worth mentioning here that the solver is not a natural language processor. When I talk about it making interferences from the clue, the solver is really just parsing an attached markup that encodes the information of the text in a format it can understand. For example, "Abigail is a Baroness" would be marked up as
- [forename]:(Abigail):[1],
- [forename,nobility]:(Abigail,Baroness):[1].
The first term tells the computer there is exactly one Abigail, the second that there is exactly one Baroness Abigail, and so they are one and the same; Abigail is indeed a Baroness. There's a nuance to encoding more complex sentence structures, but the markup is such that for every entry in a bank of clues, a human writer can in theory go through and tag them with the bounds they need to be read by the solver.

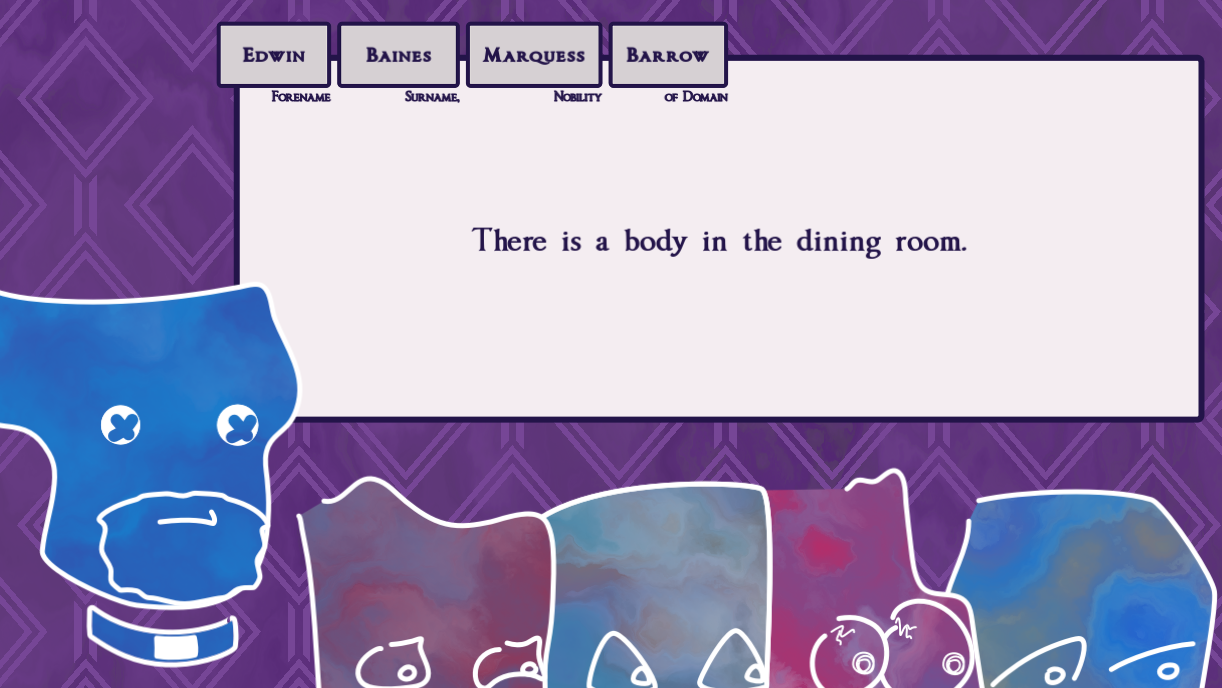
You Got Me Monologuing The player's main sources of information are the suspects' firsthand accounts of the murder, but there may also be visual signifiers of, say, a character's gender.
...In theory. In practice, we're just creating more work for our text generator. The task bifurcates into generating both human-readable prose, and markup that tells the computer the exact same information - and any discrepancies between the two could render the puzzles unsolvable.
Bad Bohemians uses a stochastic, context-sensitive grammar to put its prose together, Mad Libs-style, recursively filling in the blanks of a prewritten sentence structure with prewritten phrases (which may contain more blanks of their own). Where the markup presents a challenge is we need to feed it back into the grammar as we generate it. It's a chicken and egg scenario, in that the computer needs to understand what constraints its under to correctly set said constraints!
The Sincerest Form Of Flattery Whenever three or so characters are been correctly identified, we lock in those identities for the rest of the puzzle. It's a neat little game design trick to let the player know they're on the right track, ripped wholesale from Return of the Obra Dinn.
As Kate Compton puts it, grammars struggle to encode "high level relationships between different things generated at different points in the grammar". That's certainly true in Bad Bohemians' case, to the extent that - while I do genuinely enjoy how intuitive grammars are to work with as a writer - I may need to nuke my text generation setup in the not-too-distant future. For all the quick and dirty hacks I've found, writing longer phrases with a less dynamic markup is the only reliable method of keeping both halves of my text generator in sync. It's a shame, really, because while the path to a solution can really vary puzzle to puzzle, the player experiences that through a very same-y layer of dialogue.
Loose Ends
Don't misunderstand me: this is still a successful demo. I've created an game capable of using my own words and my own logic to generate puzzles that nonetheless challenge me. I've packaged it into a GDExtension, for easy porting into future projects. I even found the time to add juice, from the shader textures I wrote for my doodles to the Verlet rope physics I added to the pinboard UI. I'm just not done with it yet.
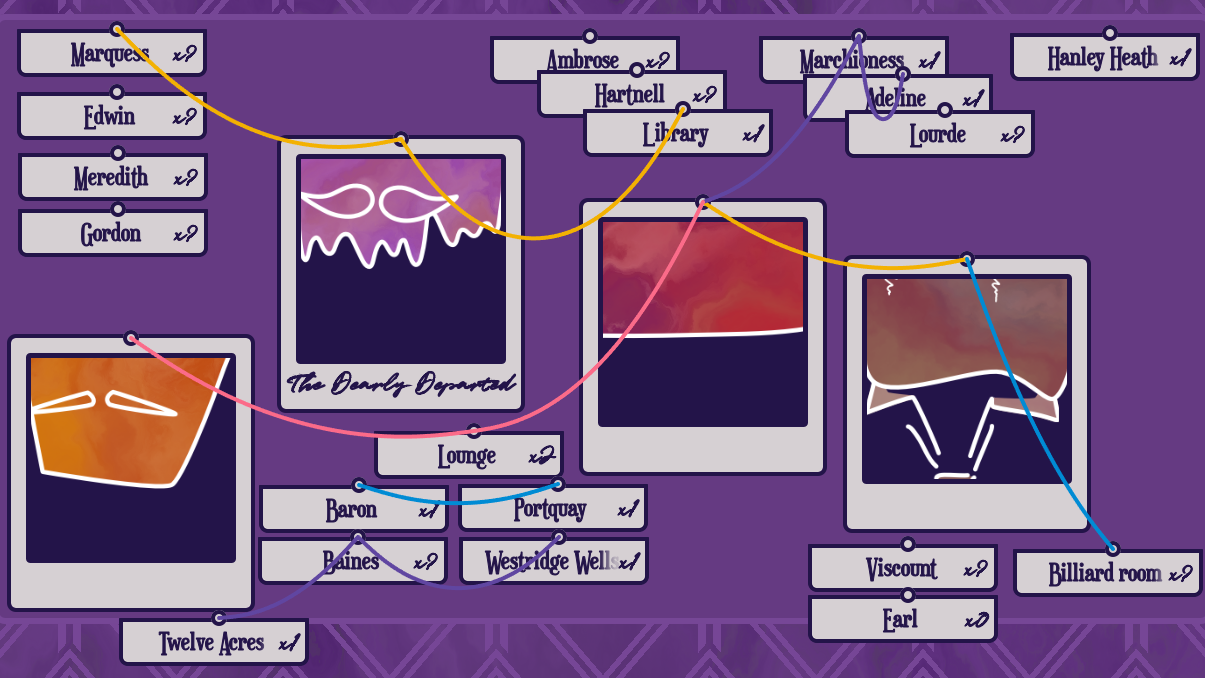
Tying It All Together The game's note-taking interface, styled as a evidence board: the player can drag polaroids and newspaper clippings about, and draw connections between them with string. It's not as versatile as the UI of, say, The Rise of the Golden Idol, but my playtesters nonetheless find it useful for organising their thoughts.
First, I'll need more debugging tools. Some of those I can find online - I'm keen to start using tracy for profiling as soon as I've switched to building with CMake instead of scons1 - but others I'm going to have create myself. So far my debug builds print some information about each puzzle to their console answers, but that's about it. Ideally, I'd want more control over how puzzles are generated, to the point where I could specify not just the number of characters but also the characteristics they have, the dialogue they use, etc. (up to now I've been finding finicky edge cases more or less through trial and error). Data visualisation tools would be useful for benchmarking variance, e.g. finding the frequency of each phrase in a sample of puzzles to test their repetitivity. Oh, and any truly full release would also need a player-facing hints system that can clearly show the solver's working, as it were, to lead users to a complete solution... but I'm still some ways off from that for now.
1 Why Godot uses scons to begin with, I have no idea. Being a real CMake amateur back when I first set Bad Bohemians up, I thought it'd make sense to follow the engine's GDExtensions documentation to the letter. Jehferson Mello and Hristo Iliev's blogs have since shown me the error of my ways, and helped me configure a far superior build system on subsequent projects.

Seeds of Doubt Seeding the whodunnits is essential for replayability - whether that's sending a particularly twist-y puzzle to a friend or reproducing a rare bug.
The other challenge is one of scale. There's only so much I can test the game with its current, limited assets - if the generator is returning the same snippet of dialogue over and over again, is that because the code is failing to produce variety, or because there's not enough writing in the game to begin with? Part of this comes from a reticence to write too much before I rework the grammar (as discussed above, I want to break down the game's existing phrases into smaller, modular chunks when I can), but part of it is something deeper. Bad Bohemians has been fun, but it's not the final form I want this project to take. Assets come later; this specific demo was about getting the generator feature-complete, or at least complete enough to convince me the remaining work will be feasible. And I think it has.